What Happens When You Type "https://www.google.com" and Press Enter?
A simplified breakdown of how a website request gets resolved

Trying to be better at building out applications that matter!
Browsing on the web has become commonplace in the 21st century, and with most companies having extensions of their services (and brand) on the web, accessing websites have become necessary towards getting information, buying goods and using necessary services.
The process with which a website gets displayed on the browser, is unfortunately much less known. From the input of a URL to the website's content being displayed on a screen, there are operations that have to take place which are important towards getting results (in the form of the web content) from your inputted URL.
Prerequisites:
A browser from which you can input the website URL and see results.
A working internet connection.
A website URL to access. We'll be using "www.google.com" as an example.
1. DNS Request
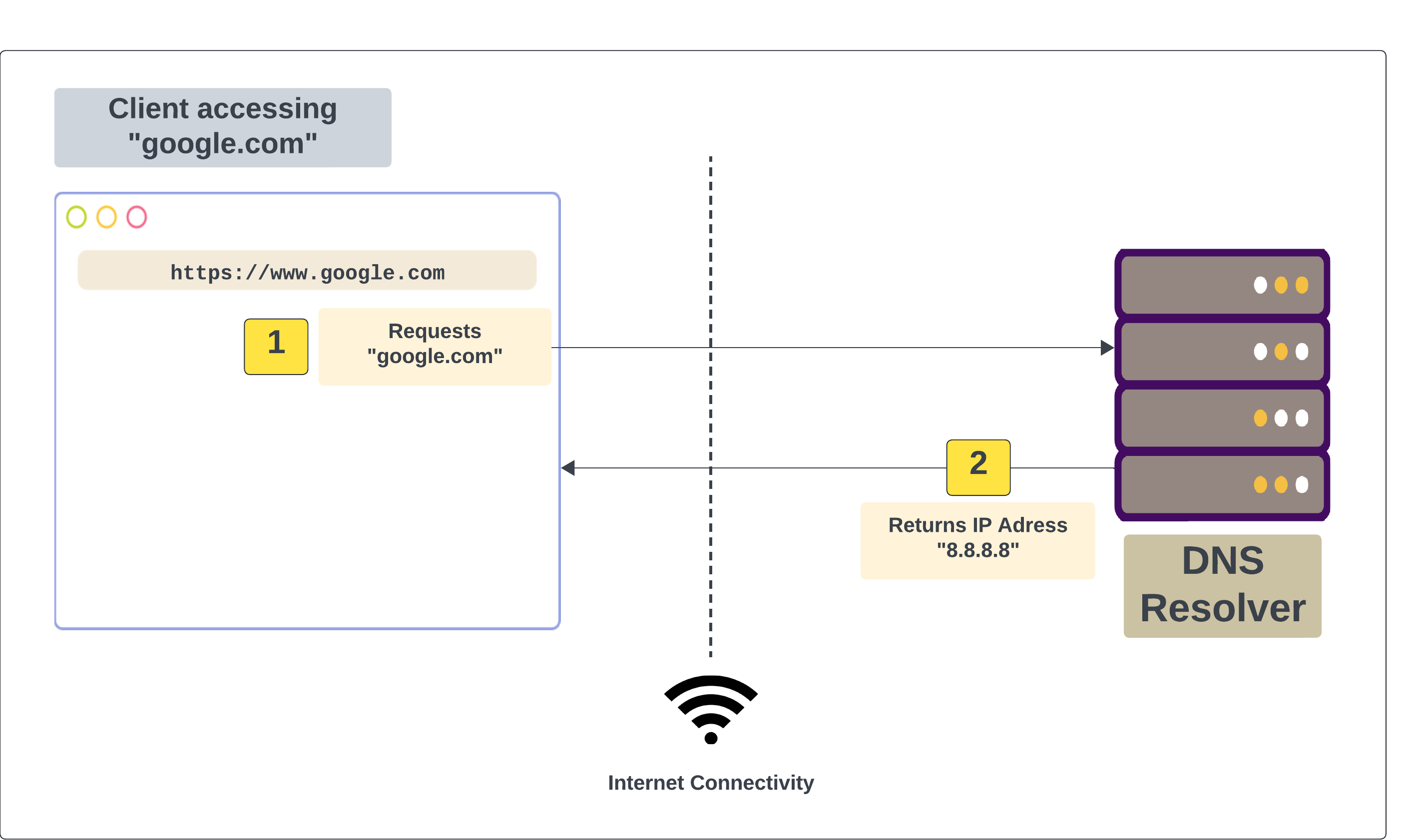
All computers with access to the internet (including the one that contains the web content you need) all have a unique number called its "IP Address". IP addresses are used to recognize each device that is on the internet, as well as their location and how to access them; pivotal for communication among one another. To access a site, you need to get the site's content from the computer hosting it. To access the computer hosting the site, you need its IP Address, and this IP Address is what you have in a form; the website URL.
The website URL is an alias for the IP Address, as it is easier to remember words than a pair of numbers. Converting the URL to the IP Address is where the Domain Name System (DNS) come into play.
After inputting the URL in your browser, it sends a DNS request to translate the URL into an IP address that the browser will understand and will be able to access. This request is usually sent to a DNS resolver, which then queries authoritative DNS servers to find the IP address, sending it as a response to your browser.
2. TCP/IP, HTTPS and Firewalls

The browser, after getting the IP Address from the DNS Resolver, then goes on to make a connection to the computer that "resides" on the IP Address. The browser makes a Transmission Control Protocol (TCP) connection to the IP Address alongside other Internet Protocol (IP) rules. TCP makes communication between the browser and the requested IP Address reliable by breaking data into packets and reassembling them at the destination.
Following the TCP protocol to exchange data, the browser can send these packets of data as plain text (using HTTP), or as encrypted data (HTTPS). Hypertext Transfer Protocol Secure (HTTPS) is an extension of Hypertext Transfer Protocol (HTTP), it uses SSL Certificates to validate the identity of the destination computer ("google.com" computer in our case). This safeguards information sent between both parties, an important part of web security.
At this point, the request is made and leaves the client-side (which is your browser) heading towards the server-side (Google's computers) for a response.
On reaching Google's computers, the first point of contact for the request is a network "barrier" called the Firewall. A firewall typically acts as a barrier between the server and an untrusted network, such as the Internet, where our request is coming from. This particular firewall makes sure that only encrypted requests (HTTPS requests) are able to get through it to the servers.
3. Load Balancers and Servers
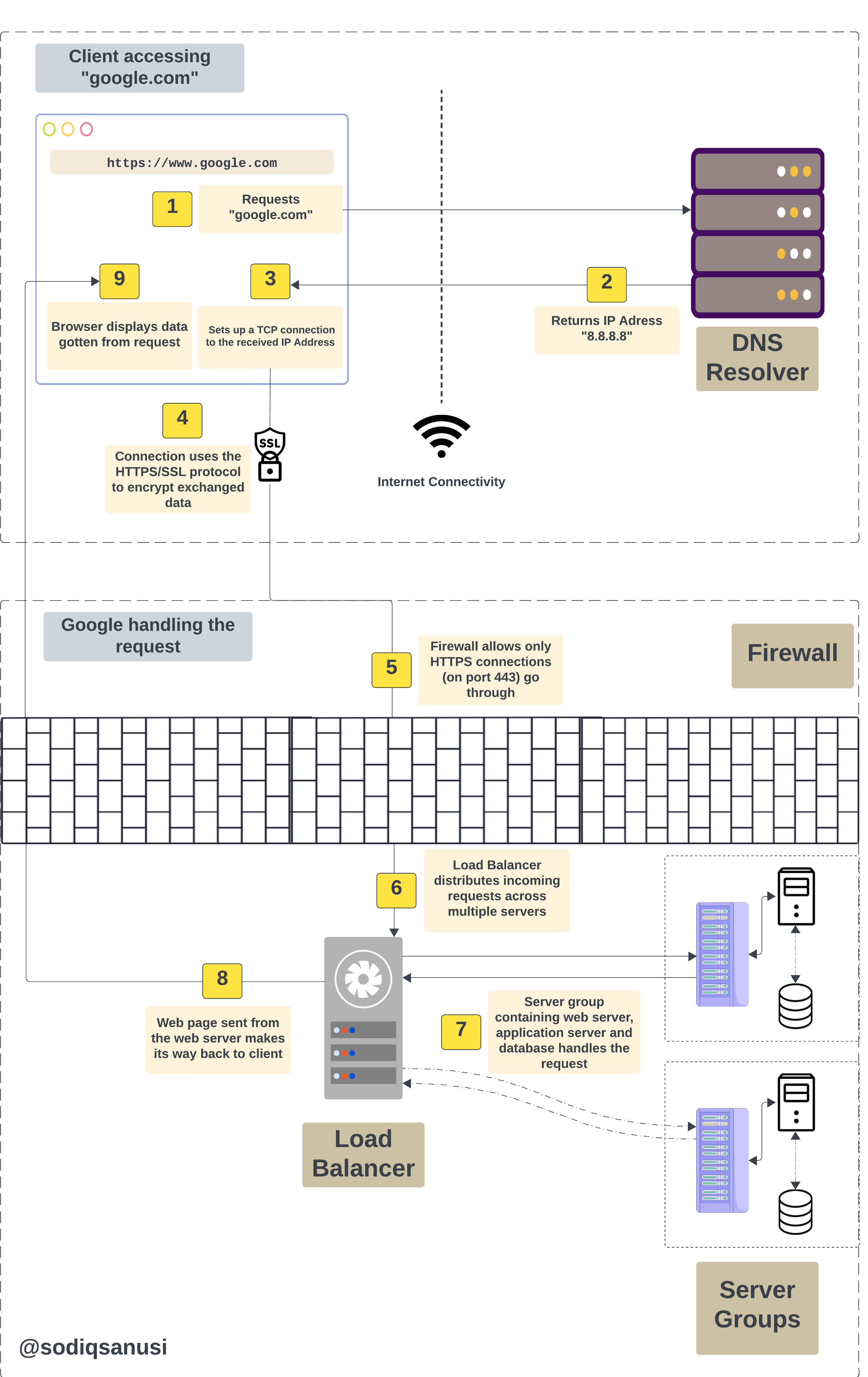
Requests that make it past the firewall then go to a Load Balancer. Load balancers distribute incoming network traffic across a group of backend servers (a.k.a. Server Groups) so that no server group is overwhelmed with requests, optimizing performance across all available servers and reducing response time (i.e. the time it takes for the site to "load") back to the client.
A Server group consists of two or more servers alongside a database, all working together to process requests as a functional unit. High performance applications usually have multiple server groups, with a load balancer distributing traffic among them efficiently.
A typical server group for a website consists of a database, an application server, and a web server. The database stores user data, which can be retrieved to generate dynamic content for the website. The application server majorly works on interacting with the database, executing server-side scripts while running application logic. Handling the HTTPS/HTTP requests then falls to the web server, the web server also handles retrieving static content such as images, HTML, and JavaScript files, creating the foundation of the webpage to be displayed.
Basically, the application server interacts with the database to create dynamic content and perform some application logic. The web server then uses the created content from the application server as data in the webpage it returns to the user.
Conclusion
This article is mostly a surface-level explanation of the processes that goes into resolving a website request. Each of the steps outlined here is more complex than what was discussed, and I do advise further research into them (especially if you are interested in Systems Administration and DevOps as a software engineer).
This article was inspired by an assignment in my Software Engineering course, you can check on how that is going for me in this series!
So yea; sayōnara, ciao, [insert goodbye in your native language here], byee🫶🏾.

